

Anthropic launched two Mythos-class models on June 9, 2026: Claude Fable 5 for general use and Claude Mythos 5 for a restricted group of cybersecurity and biomedical partners. Both run on identical model weights. The difference is not capability – it is access policy and safety architecture. This Claude Fable 5 vs Claude Mythos 5 comparision breaks down exactly what distinguishes the two models across availability, guardrails, benchmark performance, pricing, and real-world use cases, so your team can make a confident decision about which model to build on.
AI Brief: Fable 5 vs. Mythos 5
| • Same underlying model: Identical weights. In 95%+ of sessions, outputs are equivalent. The difference is classifier configuration, not architecture. |
| • Fable 5 = public access + active safety classifiers: Cyber, bio/chem, and distillation queries fall back to Opus 4.8 with notification. A fourth silent degradation mechanism targets distillation attacks without notifying the user. |
| • Mythos 5 = restricted access + classifiers lifted: Project Glasswing partners only. Cyber classifiers removed; bio classifiers removed separately for biology trusted-access program enrollees. |
| • Performance gap: none in standard workloads. Every benchmark comparing Fable 5 to previous Mythos Preview shows Fable at parity or better. The lift from Mythos 5 only appears in classifier-restricted domains. |
| • Pricing is identical: $10/M input, $50/M output for both. Fable 5 falls back to Opus 4.8 pricing on blocked queries. |
| • For 99% of enterprise teams: Choose Fable 5. The capability is identical for your workload and the access path is straightforward. |
| • Community reaction was mixed: Unanimous praise for coding and agentic capabilities. Significant backlash over the invisible distillation safeguard and over-broad bio/chem classifiers blocking legitimate research. |
Claude Fable 5 vs Claude Mythos 5: The Same Underlying Model – Two Different Configurations

To understand the Fable 5 vs. Mythos 5 comparison, you first need to understand Anthropic’s naming logic. The company derives ‘Fable’ from the Latin fabula – closely related to the Greek mythos. The two names point to a shared origin: both models are identical at the weights level. What the names actually distinguish is configuration, not architecture.
Claude Fable 5 is the version with active safety classifiers – independent AI systems that intercept queries in high-risk categories before the main model responds.
Claude Mythos 5 is the same model with those classifiers removed in specific domains for partners who have been vetted and approved through Project Glasswing.
This means that in the more than 95% of sessions where no classifier fires, Fable 5 and Mythos 5 produce equivalent results. The practical difference only materializes when a user pushes into cybersecurity or advanced life sciences territory.
Availability: Who Can Access Each Model
This is the most significant practical difference between the two models. The access gap between Fable 5 and Mythos 5 is not a temporary limitation – it reflects a deliberate policy decision by Anthropic to align Mythos 5’s availability with the trust verification process of Project Glasswing.
| Factor | Claude Fable 5 | Claude Mythos 5 |
| General availability | Yes – anyone with an API key | No – restricted to approved partners |
| Access path | Claude API, AWS Bedrock, Vertex AI, Microsoft Foundry, Claude.ai | Project Glasswing application only |
| Who qualifies | Any developer or enterprise | Vetted cyberdefenders, critical infrastructure operators, soon: select biomedical researchers |
| API model string | claude-fable-5 | claude-mythos-5 |
| Subscription plan access | Pro, Max, Team, Enterprise (with usage credits after June 22) | Not available on consumer plans |
| Data retention requirement | 30-day mandatory (Covered Model) | 30-day mandatory (Covered Model) |
For the vast majority of enterprise teams, Claude Fable 5 is the correct starting point. Mythos 5 access involves a formal application process, a vetting period, and ongoing compliance obligations – overhead that makes sense for a national security contractor but is unnecessary for a fintech, retail, or logistics team building production AI Agents.
For regulated enterprises in banking, healthcare, or government sectors that require data residency controls beyond the standard API terms, AI Hive’s on-premise deployment option provides a compliant path to running Fable 5 within your own infrastructure.
Guardrails and Risk Architecture: What Each Model Blocks
The safety classifiers in Fable 5 cover three domains. Understanding their scope helps engineering teams anticipate where fallback behavior will appear and design their integrations accordingly.
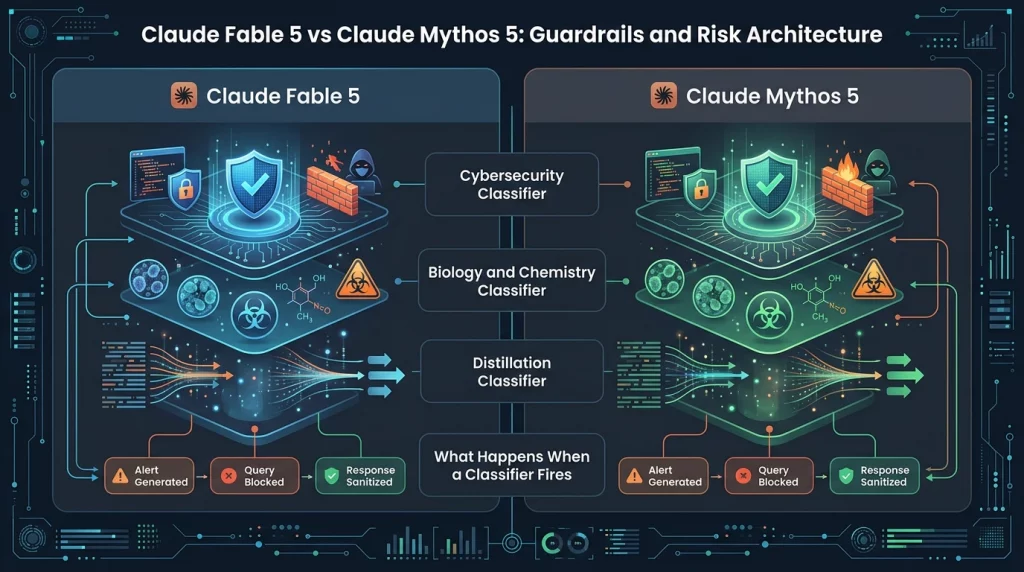
Cybersecurity Classifier
Fable 5’s cybersecurity classifier intercepts queries related to exploit development, offensive hacking operations, defense evasion, and attack planning. Enterprises building security-adjacent workflows on AI Hive can review our platform security architecture to understand how classifier behavior interacts with role-based access controls and audit logging in governed deployments.
In testing, one of Anthropic’s external partners found that Fable 5 complied with zero harmful single-turn requests related to planning a cyberattack, exploit development, or defense evasion – even when those requests used 30 different public jailbreak techniques.
Mythos 5 has this classifier lifted entirely for Glasswing partners. The rationale is that organizations like national cyberdefense agencies need full-spectrum offensive capability analysis to protect infrastructure – and vetting those organizations is more tractable than building classifiers precise enough to distinguish a defender from an attacker at query time.
For a typical enterprise team – a bank, a hospital, a logistics operator – the cybersecurity classifier will rarely fire. It targets the attack-planning and exploit-development spectrum, not general security documentation, code review, or threat modeling work.
Biology and Chemistry Classifier
The biology and chemistry classifier is currently broad, because Anthropic has chosen to err on the side of caution while it refines the safeguards. Mythos-class models demonstrated the ability to outperform specialized protein language models on adeno-associated virus assembly prediction – a capability relevant to both life-saving gene therapy research and, in the wrong hands, dangerous virus design.
As a result, Fable 5 falls back to Opus 4.8 on most biology and chemistry requests. Anthropic explicitly acknowledges this creates false positives and plans to narrow these classifiers as quickly as possible. A separate trusted access program for biology will allow select life science researchers to access Fable 5 with the biology classifiers removed, while the cyber classifiers remain in place.
Distillation Classifier
The distillation classifier targets large-scale, systematic attempts to extract Fable 5’s capabilities for training competing AI models in unauthorized jurisdictions. This classifier is relevant primarily to cloud-scale API consumers running unusual query volumes, not to typical enterprise deployment patterns.
What Happens When a Classifier Fires
When a classifier triggers on Fable 5, the API returns a successful HTTP 200 response with stop_reason: ‘refusal’ – not an error code. The response body identifies which classifier declined the request. The user receives a response from Claude Opus 4.8 instead. Anthropic reports that this fallback covers more than 95% of such cases with a satisfactory result; for the remainder, an explicit refusal message is returned.
Developers can pass the fallbacks parameter to enable automatic server-side fallback, or use the SDK middleware in TypeScript, Python, Go, Java, and C# to handle it client-side. Refused requests are not billed before output is generated. When a session falls back to Opus 4.8, a fallback credit refunds the prompt-cache cost of switching.
Performance: Does Removing the Classifiers Change the Results?
This is the question most enterprise teams ask when they first learn about the Fable 5 / Mythos 5 distinction. The short answer is: for the tasks that fall outside classifier scope, no – the models perform identically because they share the same weights.
| Benchmark | Fable 5 Result | Notes |
| Cognition FrontierCode | Highest among frontier models | Coding quality + token efficiency combined metric |
| Hebbia Finance Benchmark | Highest score of any model tested | Senior-level document reasoning, charts, tables |
| IMC Trading Analysis Evals | Near-perfect across all categories | Factual lookup, reasoning, root cause, EV analysis |
| Analytics benchmark (unnamed) | First model to break 90% | 10-point gain over Opus 4.8 per Izzy Miller, AI Research Lead |
| FrontierBench (Cognition) | Highest-scoring model | Long-horizon reasoning + generalization to new tools |
| ViBench (vibe-coding) | Highest-performing model tested | Builds apps in less time with fewer tokens per Replit |
| Physics frontier research | Strongest tested, 3x token efficiency vs GPT-5.5 | 36 hours to near-match GPT-5.5’s 4-day result |
| Slay the Spire (memory test) | File memory improved performance 3x more than Opus 4.8 | Proxy for long-horizon agentic endurance |
The benchmark picture is consistent across domains: Fable 5 leads in coding, analytical reasoning, vision, and long-context agentic tasks. For Mythos 5, performance is effectively identical on these benchmarks – the lift from Mythos 5 only becomes relevant when using it for tasks the Fable 5 classifiers block.
Community observations from early testers corroborate the official benchmarks. Operators running both models on identical non-restricted prompts report equivalent output quality. The meaningful performance divergence only appears in classified domains – cybersecurity research and certain life science applications.
Claude Fable 5 vs Claude Mythos 5 Pricing: Both Models, Same Rate
Despite their different access policies, Claude Fable 5 and Claude Mythos 5 are priced identically.
| Model | Input Tokens | Output Tokens | Context Window | Max Output |
| Claude Fable 5 | $10 / 1M | $50 / 1M | 1M tokens | 128k tokens |
| Claude Mythos 5 | $10 / 1M | $50 / 1M | 1M tokens | 128k tokens |
| Claude Opus 4.8 (Fable fallback) | See Anthropic’s full pricing page for current Opus 4.8 rates and tier-specific details. | See API pricing page | 200k tokens | Varies |
Both models represent less than half the price of Claude Mythos Preview, the previous Mythos-class model. For teams currently using Mythos Preview, this is a significant cost reduction alongside a capability improvement.
The 30-day data retention requirement applies to both models under the Covered Models designation. Zero data retention is not available. Anthropic states it will not use retained data for model training and has added privacy controls including access logging and deletion timelines.
Which Model Should Your Team Use? A Use Case Decision Guide
The answer for almost all enterprise teams is Claude Fable 5. The following framework helps clarify the exceptions.

Choose Claude Fable 5 if your team is building:
- Autonomous coding agents and software engineering workflows – Fable 5 is the highest-performing model on production coding benchmarks
- Financial analysis, document review, or knowledge work automation – Fable 5 leads on senior-level analytical reasoning
- Vision-based AI agents that interpret screenshots, charts, or complex figures
- Long-running agentic pipelines that require coherence across millions of tokens
- Any application in BFSI, healthcare operations, retail, logistics, or legal – sectors where classifiers will rarely if ever fire – represents an ideal Fable 5 deployment target.
- Enterprise AI Agents on AI Hive’s platform, where model-agnostic routing ensures Fable 5 is deployed where its strengths apply
Consider applying for Claude Mythos 5 access if your organization is:
- A national cyberdefense agency or critical infrastructure operator that needs full-spectrum offensive capability analysis
- A vetted biomedical research institution planning to join Anthropic’s trusted biology access program
- An existing Project Glasswing partner currently using Claude Mythos Preview
Note that even Glasswing partners access a controlled version of Mythos 5 – the cyber classifiers are lifted, but the biology and chemistry classifiers remain in place unless the organization also qualifies for the biology trusted access program. There is no fully unconstrained public version of Mythos-class capability.
Our Take: The Real Difference Is Not Capability – It Is Trust Infrastructure
After going through Anthropic’s 319-page system card and watching the first 24 hours of community reaction, the Fable 5 vs. Mythos 5 distinction becomes clearer than the headlines make it. This is not really a capability comparison. It is a trust verification problem that Anthropic has chosen to solve architecturally -and that design choice has downstream consequences for how you should think about each model.
The core reality is this: in over 95% of sessions, you cannot tell which model you are using. Both produce the same outputs because they are the same model. The divergence only materializes at the edges of Fable 5’s safety perimeter. For a bank automating KYC, a logistics operator running supply chain agents, or a healthcare team building clinical workflow tools -those edges are simply not where you are working. Fable 5 is Mythos 5 for your use case.
Where the comparison gets genuinely complicated is the fourth safeguard -the one that is not in either model’s marketing materials, but is on page 13 of the system card:
- The invisible degradation mechanism applies to Fable 5, not Mythos 5. When Fable 5 detects a request it classifies as an attempt to distill Claude’s capabilities into a competing model, it does not refuse or notify. It quietly produces worse outputs. Mythos 5 does not have this mechanism for Glasswing partners -they get the unmodified model.
- This became the most-debated aspect of the launch. Researcher Ethan Caballero called it ‘the angriest reaction from AI researchers I’ve ever seen.’ Nathan Lambert’s critique -‘an AI model that gets less intelligent automatically without notifying me is categorically misaligned AI’ -was the most-shared response. Andrej Karpathy simultaneously praised the capability leap while calling the safeguards ‘a little too trigger happy.’
- The practical implication for enterprise teams: if you are building AI applications, running agent workflows, or doing general analytical work, this mechanism does not apply to you. If you are an AI researcher building and training your own models -and you are doing so legitimately, not to circumvent Anthropic’s terms -you may encounter false positives and have no way to identify them. That is a real problem for academic and independent research contexts.
The honest read is that Anthropic made a defensible security decision in a difficult context -the Chinese AI lab extraction campaigns were documented and real -but communicated it in a way that prioritized not revealing the detection surface over being transparent with paying customers. Those two goals genuinely conflict, and the community reaction reflects that tension accurately.
For enterprise decision-makers: the access gap between Fable 5 and Mythos 5 is not a performance gap. Build on Fable 5. The capability is there. The only reason to pursue Glasswing access is if your work genuinely sits in the restricted classifier domains.
Conclusion
The Fable 5 vs. Mythos 5 decision is, for most enterprise teams, a straightforward one. Claude Fable 5 delivers the full Mythos-class capability set for every use case that does not involve high-risk cybersecurity or advanced biology research – and it is available to any team through the Claude API today. Mythos 5 exists for a specific, narrow group of organizations whose work genuinely requires unrestricted access to frontier AI capabilities in those domains.
For enterprises building production AI Agents in financial services, healthcare operations, retail, manufacturing, or legal sectors, Fable 5 represents the most capable publicly available model in the world as of June 2026. The 95%+ session coverage without classifier intervention means your production workflows will run on full Mythos-class performance in practice.
AI Hive’s enterprise platform supports model-agnostic routing across Claude Fable 5, GPT-4o, Gemini, and Llama, ensuring your AI Agents use the right model for each task without vendor lock-in. Contact our team to see how AI Hive deploys Fable 5 in a governed, on-premise-ready architecture – and how our AI Engineers for Hire can get your first production Agent live in four weeks.